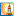PYoCo es un modelo de difusión de texto a video
PYoCo es un modelo de difusión de texto a videoInvestigadores de NVIDIA, la Universidad de Chicago y la Universidad de Maryland han presentado PYoCo, un modelo innovador a gran escala que combina texto y video. Este modelo se basa en el exitoso eDiff-I, un avanzado generador de imágenes, pero incluye una novedosa técnica de video de ruido previo.
Según los desarrolladores, PYoCo incorpora diversas técnicas eficaces de investigaciones anteriores, como la atención temporal, el refinamiento conjunto de imágenes y videos, una arquitectura de generación en cascada y un conjunto de eliminadores de ruido expertos.
Nos referimos a mejoras que permiten superar a otros métodos en múltiples conjuntos de datos de referencia. En el documento compartido por el equipo, también se destaca la capacidad del modelo para lograr una síntesis de video de alta calidad sin necesidad de material de referencia, ofreciendo un fotorrealismo superior y una consistencia temporal excepcional.
Puedes obtener más información sobre el desarrollo aquí.
×
 Lo primero
+ Preguntar sobre
Lo primero
+ Preguntar sobre
Configuración
Mi perfil
Contacto
Mail al administrador
- Animación y Rigging
- Errores de programa
- Hardware
- Iluminación
- Impresoras 3D
- Modelado
- Partículas y Dinámicas
- Plugins
- Postproducción
- Render y Cámaras
- Script
- Texturas y Materiales
- Videojuegos
Configuración
Mi perfil
Contacto
Mail al administrador

 Citar
Citar