Inteligencia artificial en Cascadeur. Eugene Dyabin, Aina Chirkova y Max Tarasov de Nekki han compartido una descripción completa de la herramienta impulsada por IA de Cascadeur para posar personajes en 3D.
Introducción
Hola, soy Eugene Dyabin, cofundador del renombrado editor de juegos Nekki y también productor sénior de la herramienta de animación de personajes basada en IA Cascadeur. Después de obtener una maestría en matemáticas aplicadas en 2006, mi equipo y yo creamos la serie de juegos Shadow Fight de éxito internacional y la convertimos en la serie de juegos de lucha para dispositivos móviles más jugada, con más de 500 millones de descargas.
También soy un ávido desarrollador de códigos que participa activamente en la programación de Cascadeur. Mi objetivo personal es hacer de Cascadeur un ChatGPT para la animación de personajes, lo que permite incluso a los principiantes crear animaciones físicamente realistas a nivel profesional.
En colaboración con dos especialistas en inteligencia artificial de mi equipo, Aina Chirkova y Max Tarasov, me gustaría contarles cómo se nos ocurrió una herramienta inteligente para hacer que la pose de personajes en el desarrollo de juegos sea más fácil y rápida y cuánto tiempo nos tomó realmente hazlo funcionar.
Grandes avances neuronales
Cada vez que ocurre otro gran avance de la red neuronal, por ejemplo, Midjourney o DALL-E, que hace magia real, provoca una exageración bien merecida. Pero cuando se trata de convertir las redes neuronales en herramientas utilizables para realizar tareas creativas, tener el control se convierte en el factor más importante. Resulta que casi todos los artistas quieren tener un control completo sobre cada trazo y cada matiz que hacen. ¡Lo cual es razonable!
Eso es exactamente lo que enfrentamos cuando desarrollamos nuestra herramienta AutoPosing para nuestro software de animación de juegos Cascadeur, que permitiría a los animadores crear poses naturales usando la menor cantidad de controladores posible. Queremos contarles cómo obtuvimos un resultado interesante por primera vez con la ayuda de una red neuronal bastante profunda e inteligente, y luego pasamos más de un año reelaborando todo, dividiéndolo en un montón de redes neuronales más pequeñas y simples y heurística. algoritmos, agregando diferentes excepciones y configuraciones. Y todo eso solo para garantizar que los animadores obtengan el máximo control y previsibilidad.
Queremos mostrar que existe una gran brecha entre la magia desenfrenada completamente automática y una herramienta que realmente se puede usar para trabajar.
La primera iteración
Nuestro objetivo era desarrollar una herramienta que permitiera a los animadores configurar rápidamente poses preliminares y perfeccionarlas después. De esta manera, hacer cada pose podría volverse varias veces más rápido.
La idea inicial era bastante simple: alimentar la posición de solo 6 puntos (cuello, pelvis, muñecas y tobillos) en la red neuronal para sugerir la pose más natural con estos puntos conservando sus posiciones.
Para enseñarlo, tomamos 1300 animaciones de nuestro juego Shadow Fight 3. Luego hicimos un conjunto adicional de poses raras especiales. Reflejamos todo para duplicar el conjunto de datos y terminamos con 2600 animaciones con un total de 220 000 poses, el 80 % de las cuales usamos para enseñar y el 20 % restante para probar.
El concepto de enseñanza era simple. Tomamos 6 puntos de cada pose y los ingresamos en la red neuronal. Sugiere la posición del resto de los puntos. Luego comparamos la posición de estos puntos con los de la pose inicial y estimamos las desviaciones. La red aprende a través de un algoritmo de retropropagación utilizando la pérdida de error cuadrático medio.
El resultado resultó ser bastante interesante:

resultados de cascadeur con IA
Luego hicimos el sistema más complejo introduciendo varias redes neuronales internas, donde la salida de una se alimentaba con la entrada de otra. Este sistema permitía al usuario controlar no solo los 6 puntos, sino todos los puntos del equipo para que los animadores pudieran mejorar la pose utilizando cualquier cantidad de puntos, todos ellos si era necesario.

Inteligencia artificial en Cascadeur con redes neuronales
La tarea parecía estar resuelta. Obtienes control total sobre la pose, y la red neuronal ayuda y ahorra tiempo.
Pero en realidad, trabajar con esa versión de AutoPosing resultó bastante molesto. El problema principal era que era impredecible. Cuando no entiendes lo que está pasando, terminas luchando contra la red neuronal en lugar de dejar que te ayude. La red neuronal resultó ser demasiado creativa, siempre intentaba adivinar cosas que no querías. Mientras estabas moviendo los 6 puntos principales, la cabeza giraría debido a alguna lógica interna, junto con los pies y las muñecas, la columna se doblaría. Aunque las poses resultaron muy bien, el proceso fue bastante frustrante.
Lo que tenemos ahora
Pasamos por múltiples iteraciones y realizamos muchos experimentos, probamos varios enfoques y, al final, pasamos más de un año para obtener un resultado que fuera conveniente para usar en el trabajo real.
Entonces, el punto principal es que en lugar de tener una red neuronal ingeniosamente complicada, tenemos un sistema complejo de 12 más simples. Cada red neuronal hace su propio trabajo o controla una región específica del cuerpo, y algunas de ellas se involucran solo en casos específicos. Algunos comportamientos del sistema los logramos sin usar redes neuronales en absoluto, reemplazándolos con algoritmos heurísticos.
Veamos qué parámetros de caracteres se resuelven mediante qué redes neuronales y algoritmos.
Dirección General del Personaje
La dirección general se resuelve mediante una red neuronal totalmente conectada que consta de 2 capas ocultas de 200 y 100 neuronas.
Dirección General del Personaje
Esta red neuronal resuelve la dirección de todo el personaje utilizando 4 puntos (Muñecas y Tobillos).
El caso es que durante el proceso de aprendizaje del resto de redes neuronales, todas las poses utilizadas se orientaron de la misma manera, con la Pelvis y el Cuello colocados en el eje Y, y el Pecho vuelto hacia el eje X. De esta forma se acota el espacio de posibles posiciones del resto del cuerpo y no depende de la orientación del personaje. Por lo tanto, para que AutoPosing funcione, primero debemos obtener la dirección general del personaje de Wrists and Ankles, para que el resto de las redes funcionen en relación con eso.
El animador también puede establecer esta dirección manualmente mediante el controlador de dirección. En ese caso, esta red neuronal se omite y se toma la dirección establecida para realizar más cálculos. Si no se establecen las posiciones de las muñecas, solo los tobillos, la dirección del personaje se determina de manera trivial: horizontal y perpendicular a la línea que conecta los tobillos.
Posición de las muñecas
Una red neuronal totalmente conectada con 4 capas ocultas (150, 200, 150, 100).

Posición de las muñecas
La posición de las muñecas depende de la posición de los tobillos, que siempre establece el usuario. También depende del controlador de dirección del personaje.
Asumimos que si el usuario coloca los tobillos cerca del suelo y no los separa demasiado, es probable que espere obtener poses de locomoción, por lo que se usaron poses del conjunto de datos de locomoción en el proceso de aprendizaje. Por ejemplo, al mover el pie derecho hacia adelante, el brazo derecho se mueve hacia atrás.
Posición de Pelvis y Cuello
2 redes neuronales (Pelvis y Neck) totalmente conectadas con 4 capas ocultas cada una (200, 250, 200, 150).

Posición de Pelvis y Cuello
La posición de la pelvis y el cuello depende de la posición de los tobillos, las muñecas y el controlador de dirección del personaje. Mientras tanto, la posición de la pelvis y el cuello entre sí está definida por un vector. Así, si el usuario establece la posición de uno, la posición del otro se determina en relación con él.
Orientación de la Pelvis
Una red neuronal completamente conectada con 3 capas ocultas (128, 30, 10).

Orientación de la Pelvis
La orientación de Pelvis depende de la posición del controlador de dirección de tobillos, cuello y pelvis (si el usuario establece este último). Además, el usuario puede rotar la pelvis alrededor de un eje usando el controlador de dirección y rotarla alrededor del eje del controlador de dirección moviendo las caderas.
Parámetros de flexión de la columna vertebral
Una red neuronal completamente conectada con 3 capas ocultas (128, 30, 10).

Parámetros de flexión de la columna vertebral
La posición de los tobillos, la pelvis y el cuello, así como el controlador de dirección del personaje, se ingresan en la red neuronal. La flexión de la columna depende principalmente de los grados de libertad que dejan la dirección del Pecho, la orientación de la Pelvis y la distancia entre la Pelvis y el Cuello. Tuvimos que hacer visualizaciones en GeoGebra como esta para visualizar todas las formas posibles en que la columna se puede doblar.
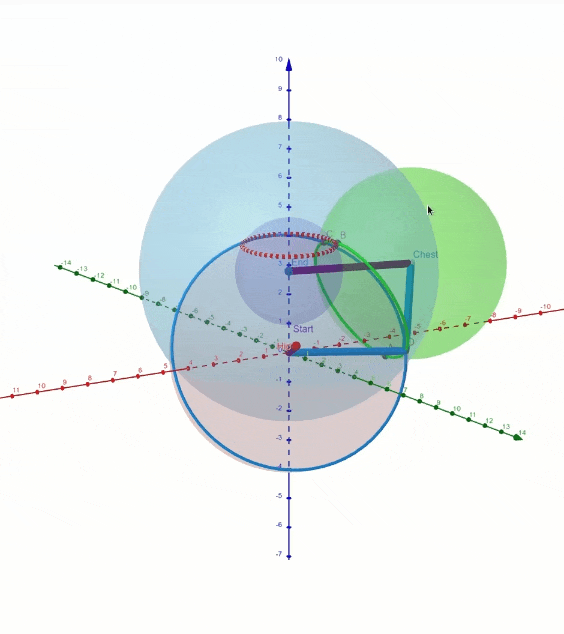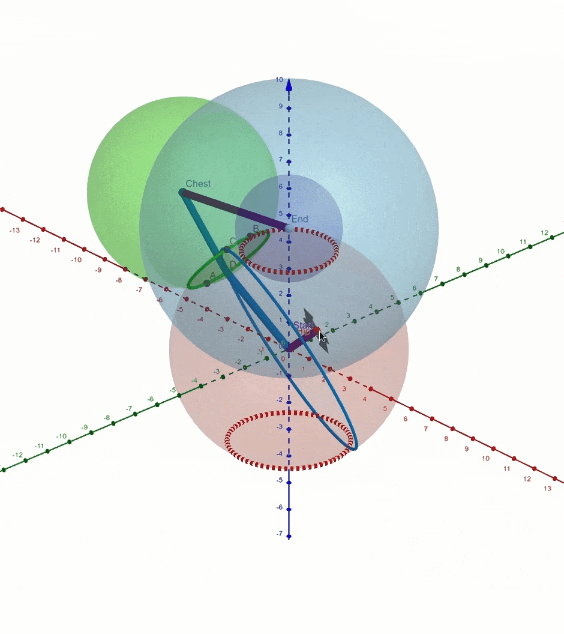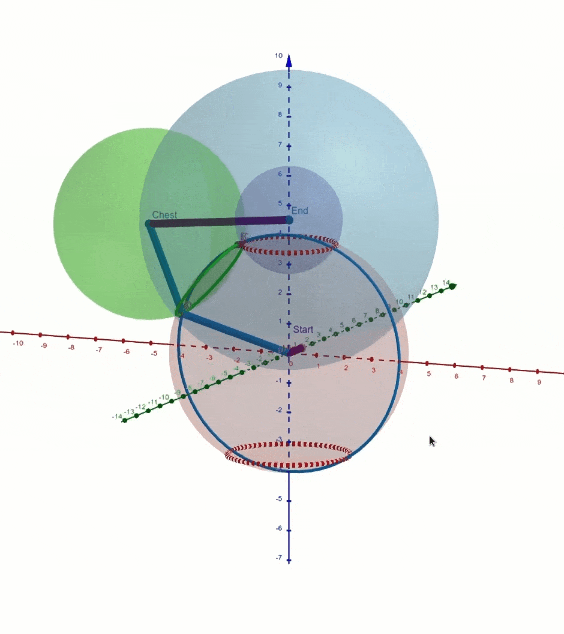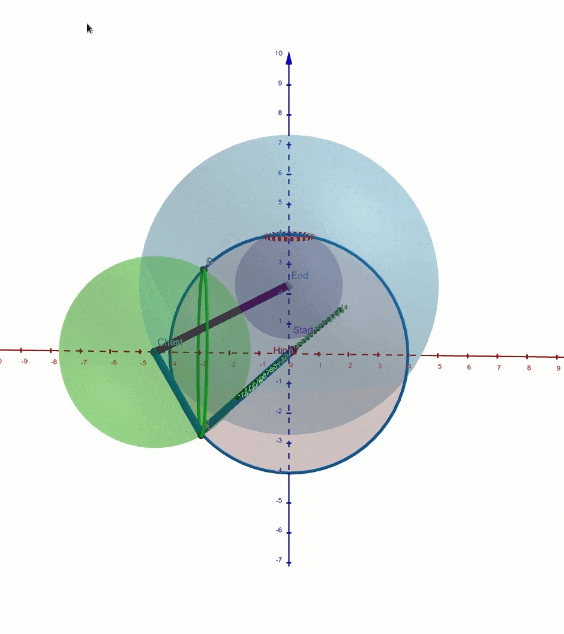
Inteligencia artificial en Cascadeur
El principal problema que resuelve esta red neuronal es en qué dirección debe doblarse la columna. Por ejemplo, las piernas determinan principalmente si la columna debe doblarse hacia adelante o hacia atrás. Otra cosa importante a mencionar es que, por defecto, la columna evita la curva en S, pero el usuario puede curvar la columna libremente ajustando la pelvis y el pecho.
La posición de todos los puntos de las extremidades
Controlado por 5 redes neuronales totalmente conectadas (manos, codos, hombros, pies y rodillas) con 2 capas ocultas cada una (64, 32).

La posición de todos los puntos de las extremidades
Estas redes neuronales determinan la orientación de las manos y los pies, así como la posición de los codos, los hombros y las rodillas.
Tenga en cuenta que las redes neuronales para los puntos de los brazos funcionan por separado para el brazo izquierdo y el derecho, evitando así cualquier influencia de los brazos entre sí. Sin embargo, las redes neuronales de los puntos de las piernas funcionan juntas, porque las piernas se influyen entre sí a través de la Pelvis.
La orientación de Manos y Pies está determinada por los 6 puntos principales (Tobillos, Muñecas, Pelvis y Cuello). La posición de los Hombros depende de la orientación de las Manos, y la posición de los Codos a su vez depende de la posición de los Hombros.
Aquí tomamos una decisión importante sobre Manos y Pies. Si el usuario no establece su orientación, la tomamos desde la posición T; de lo contrario, se comportan de manera impredecible desde la perspectiva del usuario. Una vez resuelta la posición de todos los puntos de las extremidades, los ángulos locales de Manos y Pies se restablecen a sus valores de posición T. Por lo general, las manos en una postura en T heredan la dirección de los antebrazos y los pies son perpendiculares a las espinillas.
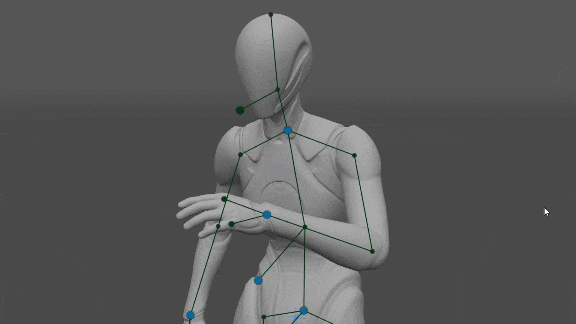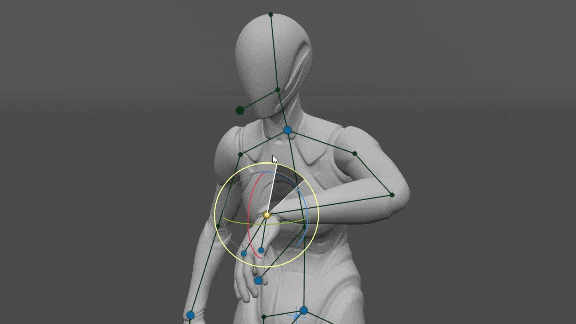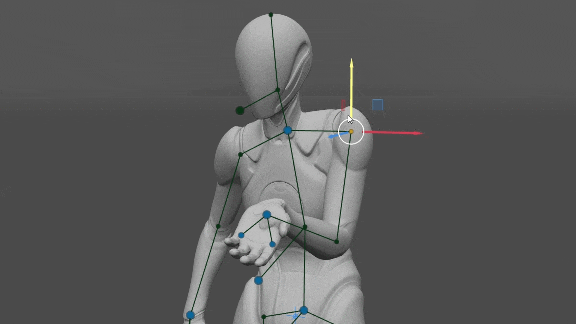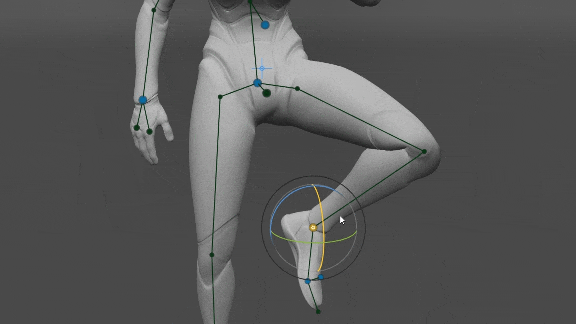
Manos y pies
Nos dimos cuenta de que si se establece la orientación de las manos, es suficiente para determinar la posición de los codos y los hombros con mucha precisión (en comparación con el conjunto de datos). Eso puede ser útil en realidad virtual, donde tenemos la orientación y la posición de las manos del jugador y necesitamos determinar la posición de los codos y los hombros y del avatar. Además, la orientación de los Pies es suficiente para determinar la posición de las Rodillas y la orientación de la Pelvis.
Alineación de pies y manos con el suelo
Este sistema no utiliza redes neuronales. Es un algoritmo totalmente heurístico.

Alineación de pies y manos con el suelo
Hay una altura particular en la que la orientación de Foot comienza a mezclarse con la de T-pose. Suponemos que en la pose T, los pies del personaje están apoyados en el suelo.
Hay algunos límites para el ángulo de la espinilla contra el suelo. Si el Pie se adelanta mucho y la espinilla supera un cierto ángulo, el Pie ya no se alinea con el suelo y se coloca sobre su talón. Si el Pie se mueve muy atrás, se queda en el suelo. Lo mismo ocurre con el movimiento hacia los lados. Además, las puntas del pie pueden chocar con el suelo. Eso permite que los dedos de los pies se doblen al tocar el suelo.
Las manos funcionan de manera similar a los pies, solo que su dirección depende del controlador de dirección del personaje.
Dirección de la cabeza
Una red neuronal completamente conectada con 2 capas ocultas (64, 32).

Dirección de la cabeza
La posición del cuello, la dirección del carácter, los parámetros de la columna vertebral y la dirección de la cabeza se ingresan en la red neuronal.
Siempre que el usuario no establezca la dirección de la cabeza, conserva su orientación relativa al pecho desde la posición en T. Pero si el usuario ajusta el controlador de dirección de la cabeza, la cabeza mirará en la dirección especificada. Al mismo tiempo, la red neuronal ajusta su inclinación, junto con la rotación del Cuello. La cabeza es la única parte del cuerpo que sabe dónde está arriba y tiende hacia su posición vertical.
Control de Todos los Puntos del Rig
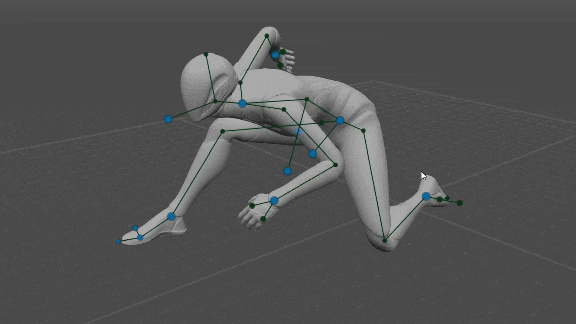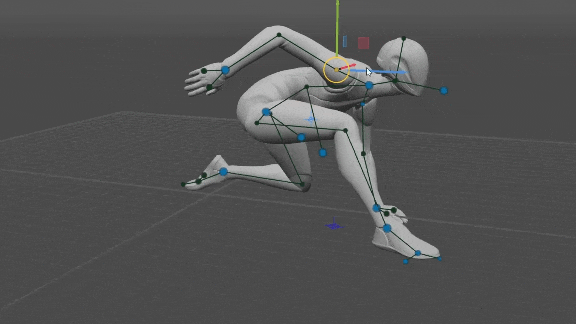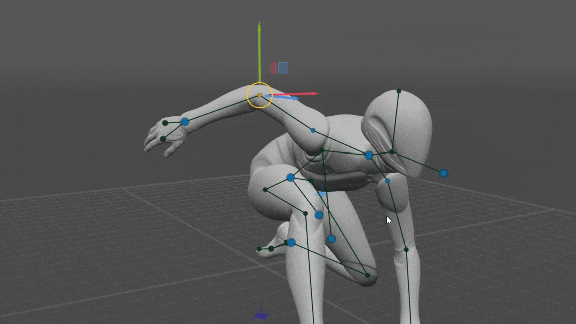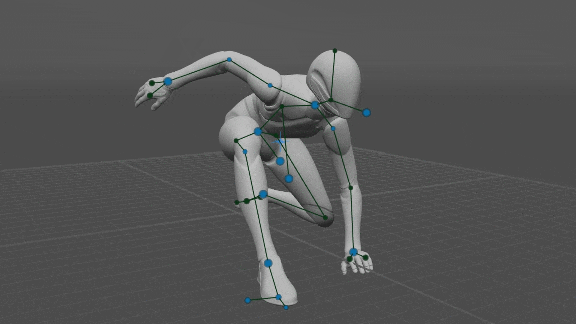
Control de Todos los Puntos del Rig
El usuario puede mover todos los puntos del equipo, es decir, codos, hombros, rodillas, pelvis y pecho. Luego, la posición resuelta por la red neuronal se ignora y, en su lugar, se utiliza la posición del usuario. Eso permite un control total sobre la pose, sin pasar por las redes neuronales por completo.
Tenga en cuenta que la orientación de las manos y los pies (si no la establece el usuario) está determinada por las posiciones de los codos y las rodillas respectivamente, porque las manos heredan la dirección del antebrazo y los pies son perpendiculares a las espinillas.
Conclusión
Hemos dedicado más de un año de arduo trabajo y numerosas iteraciones para desarrollar AutoPosing, una herramienta que ha demostrado ser realmente útil en el trabajo real. Aunque inicialmente la solución parecía prometedora, el resultado final se volvió complejo, con múltiples capas y excepciones. Sin embargo, esta complejidad es lo que hace que AutoPosing sea intuitivo y predecible, logrando su principal objetivo: ahorrar tiempo.
¿Qué es lo que realmente ahorra tiempo? En primer lugar, reduce la cantidad de movimientos del mouse que debes realizar, ya que muchos puntos de la plataforma ni siquiera necesitan ser ajustados, y para otros solo necesitas hacer pequeños ajustes. La pelvis, los hombros y la columna vertebral requieren pocos cambios, al igual que las rodillas y los codos. Además, la alineación automática de los pies con el suelo te permite girarlos horizontalmente sin afectar los otros ejes.
La segunda característica que agiliza el flujo de trabajo puede pasar desapercibida. Al crear animaciones mediante fotogramas clave, es más fácil seguir grandes movimientos, como el de una mano. Sin embargo, también es necesario ajustar los codos, los hombros y realizar cambios sutiles en la columna vertebral, lo que, cuando se realiza manualmente, puede resultar en fluctuaciones menores y una interpolación poco fluida entre los fotogramas clave. Con AutoPosing, la mayoría de los movimientos de codos, hombros, rodillas, pelvis y columna vertebral se realizan automáticamente, lo que da como resultado una interpolación suave de inmediato.
Es importante destacar que siempre tienes la libertad de realizar cambios y mantener un control total sobre el resultado final.
Esperamos que esta visión técnica de la IA de Cascadeur te resulte interesante. Puedes descargar el software de animación directamente del productor de forma gratuita.


 Cascadeur para desarrollar animaciones basadas en la física real
Cascadeur para desarrollar animaciones basadas en la física real Lo primero
+ Preguntar sobre
Lo primero
+ Preguntar sobre
 Citar
Citar