

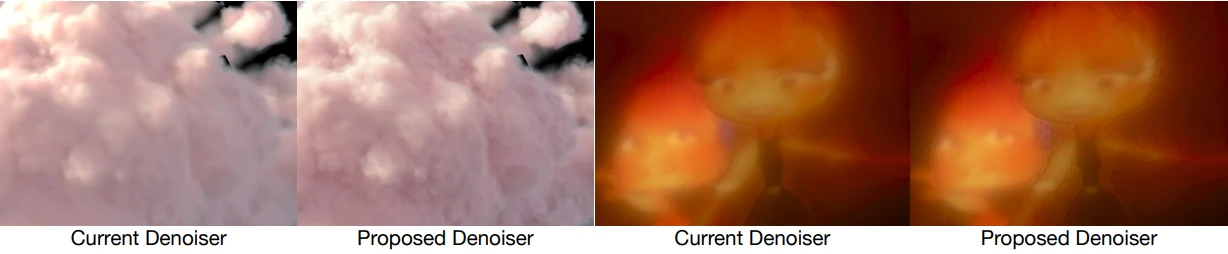
En esta figura, podemos observar claramente la mejor calidad de nuestro nuevo denoiser volumétrico en comparación con el denoiser de estudio actual. La salida de nuestro denoiser muestra una mayor nitidez y niveles más altos de detalle, especialmente notable alrededor de los bordes.
Algunos ejemplos incluyen una mayor nitidez en los límites de la nube rosa, los caracteres de fuego y el objeto a cuadros en el fondo. Estos resultados se obtienen a partir de pases de renderizado volumétrico, específicamente volúmenes FX densos y nieblas ligeras, en las películas Turning Red y Elemental de Disney y Pixar. ©Pixar
Qué es el denoising?
El denoising es un aspecto crucial de los pipelines de renderizado de producción que emplean Monte Carlo path tracing. Los denoisers basados en aprendizaje automático han demostrado ser eficaces para eliminar el ruido residual y generar imágenes limpias. Sin embargo, el denoising en el renderizado volumétrico presenta desafíos debido a la falta de características útiles y conjuntos de datos volumétricos a gran escala.
Como resultado, las secuencias denoiseadas a menudo presentan problemas como el exceso de desenfoque y el parpadeo temporal. En esta investigación, mejoramos el renderizador de producción para generar diversas características volumétricas potenciales que puedan mejorar la calidad del denoising. Empleamos un algoritmo de selección de características de vanguardia para identificar la combinación óptima de estas características.
Para entrenar el denoiser para uso en producción, reunimos miles de escenas volumétricas únicas de películas recientes y aumentamos los datos de entrada para crear un gran conjunto de datos de entrenamiento. Nuestra evaluación demuestra mejoras significativas en calidad en comparación con la versión actual en uso.
Formato de referencia ACM:
Zhu, S., Zhang, X., Röthlin, G., Papas, M., & Meyer, M. (2023). Denoising Production Volumetric Rendering. En Special Interest Group on Computer Graphics and Interactive Techniques Conference Talks (SIGGRAPH '23 Talks) (pp. 1-2). ACM.
×
 Lo primero
+ Preguntar sobre
Lo primero
+ Preguntar sobre
Configuración
Mi perfil
Contacto
Mail al administrador
- Animación y Rigging
- Errores de programa
- Hardware
- Iluminación
- Impresoras 3D
- Modelado
- Partículas y Dinámicas
- Plugins
- Postproducción
- Render y Cámaras
- Script
- Texturas y Materiales
- Videojuegos
Configuración
Mi perfil
Contacto
Mail al administrador
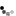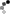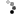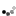
 Citar
Citar